
1. はじめに
Web上の情報は分散しており、特定の文脈で価値を最大化するには、情報の集約、補完、そして「独自の切り口」による再定義が必要です。 本プロジェクトでは、一次情報源からのスクレイピング、二次DBによる属性補完、さらに動画リソースからの視覚情報抽出とLLMによるコンテキスト再構築を組み合わせ、WordPressへのデプロイまでを完全に自動化するパイプラインを構築しました。
2. システムアーキテクチャの5段階構成
本システムは、情報の鮮度、品質、そして視覚的訴求力を両立させるため、以下の5つのモジュールで構成されています。
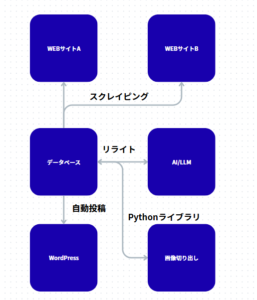
① 収集フェーズ:シードデータの抽出
リストの起点となる「一次情報元(WEBサイトA)」から、最小単位の識別情報を取得します。
-
技術的要件: 重複チェック(Unique制約)、定期実行のスケジューリング。
-
工夫点: サイトの構造変化に対応しやすいよう、要素抽出ロジックをモジュール化した設計。
② 補完フェーズ:外部API・DBとのデータ結合
一次情報のみでは不足している属性(詳細スペック、関連タグ、メタデータ)を、より詳細な情報を持つ「WEBサイトB」から引き当てます。
-
照合ロジック: 識別コード(SKUや品番など)をキーにした検索自動化。
③ メディア処理フェーズ:サンプル動画からの静止画生成
コンテンツの視覚的魅力を高めるため、提供されているサンプル動画(プレビュー)を解析し、最適なシーンを静止画として切り出します。
-
処理プロセス: 動画ファイルのストリーミング解析を行い、特定の時間間隔やフレームの明度・動きを判定してキャプチャを保存。
-
最適化: 保存した画像は、WordPressの表示速度を落とさないよう、適切な解像度とWebP形式への変換処理を自動実行。
④ 変容フェーズ:LLMによる独自性の付与
本システムの核心部です。単なる転載ではなく、検索エンジンや読者に最適化された「新定義」をAIに生成させます。
-
タイトル生成: クリック率を意識した煽り文句と、検索キーワードの含有を両立。
-
紹介文作成: 構造化された属性データをプロンプトに流し込み、文脈を持った自然な日本語文章を生成。
⑤ 配信フェーズ:CMSへのシームレスな統合
生成されたコンテンツと抽出画像をWordPress REST APIを通じて自動投稿します。
-
自動処理: アイキャッチ画像の設定、カテゴリ分類、カスタムフィールドの自動入力、およびメディアライブラリへの画像紐付け。
3. 技術的課題と解決策
データの不整合と非同期処理の管理
外部ソースからのスクレイピングや動画解析、AI生成など、処理時間が異なる工程が混在するため、同期的な処理ではボトルネックが発生します。
解決策: 各工程の進捗を管理するデータベースを構築。状態(Status)フラグを持たせることで、動画解析に失敗してもリライト工程を止めず、エラー箇所のみを後から個別リトライできる疎結合な設計を採用しました。
コンテンツの重複排除と独自性
同一作品が異なるソースで紹介されている場合、検索エンジンから「コピーコンテンツ」と判定されるリスクがあります。
解決策: 一次取得段階でのハッシュ値比較による重複排除に加え、AIプロンプトに「特定の視点(例:マニア向け、初心者向けなど)」の役割を与え、出力される語彙のバリエーションを強制的に増やすことで独自性を担保しました。
4. 考察と今後の展望
構築による成果
本システムの導入により、情報収集・メディア加工・文章作成という一連の工程に要する時間が、手動操作と比較して約90%以上削減されました。特に動画からの画像抽出の自動化は、コンテンツの「リッチさ」を維持しつつ、運用の手間を最小限に抑えることに大きく貢献しています。
今後の課題
-
画像解析の高度化: AIを用いて動画内の「盛り上がりシーン」を特定し、よりクリック率の高いサムネイルを自動選定するロジックの導入。
-
マルチポスト対応: WordPressだけでなく、SNS等のプラットフォームへ最適化された短文を同時生成・配信するマルチチャネル化。
まとめ
本システムは「情報の再定義」と「メディアの再加工」を自動化する一つの解です。単なる効率化ツールに留まらず、AIと自動化プログラムを「編集チーム」として位置づけることで、膨大なウェブデータから新たな価値を創出することが可能となります。


コメント